Project Alexandria is a research project within Microsoft Research Cambridge dedicated to discovering entities, or topics of information, and their associated properties from unstructured documents. This research lab has studied knowledge mining research for over a decade, using the probabilistic programming framework Infer.NET. Project Alexandria was established seven years ago to build on Infer.NET (opens in new tab) and retrieve facts, schemas, and entities from unstructured data sources while adhering to Microsoft’s robust privacy standards. The goal of the project is to construct a full knowledge base from a set of documents, entirely automatically.
The Alexandria research team is uniquely positioned to make direct contributions to new Microsoft products. Alexandria technology plays a central role in the recently announced Microsoft Viva Topics (opens in new tab), an AI product that automatically organizes large amounts of content and expertise, making it easier for people to find information and act on it. Specifically, the Alexandria team is responsible for identifying topics and rich metadata, and combining other innovative Microsoft knowledge mining technologies to enhance the end user experience.
The Alexandria team continues to contribute to Microsoft’s vision of enterprise knowledge, delivering essential capabilities and focusing on the future of the enterprise knowledge base and the transition from big data to big knowledge.
Microsoft Research Podcast

Collaborators: Holoportation™ communication technology with Spencer Fowers and Kwame Darko
Spencer Fowers and Kwame Darko break down how the technology behind Holoportation and the telecommunication device being built around it brings patients and doctors together when being in the same room isn’t an easy option and discuss the potential impact of the work.
Part 1: What is Viva Topics
Microsoft Viva Topics is one of the four modules of Microsoft Viva, an employee experience platform that brings together communications, knowledge, learning, resources, and insights. Viva Topics uses AI to organize resources, information and expertise into topics delivered through apps like SharePoint, Microsoft Search and Office; and coming soon to Yammer, Teams, and Outlook. Extracted descriptions, topical documents, and related sites and people are presented on topic cards that help people learn, develop new skills, and innovate faster while they work.
The Enterprise Knowledge Sharing Problem
Finding information can be hard, and numerous studies suggest that inefficiencies in knowledge searching strongly impact enterprise productivity. Solving the knowledge problem will enable employees to spend less time searching and more time learning and implementing.
A recent survey (opens in new tab) found that employees could potentially save four to six hours each week if they didn’t have to search for information—or spend time recreating it. This equates to an increase of 11-14 percent in daily productivity.
Common business scenarios such as accelerating onboarding time for new employees could be 20-35 percent faster, according to a Forrester study (opens in new tab) of the potential impact of Microsoft’s knowledge and content services.
Microsoft’s opportunity to serve customers at scale becomes real with privacy-compliant access to a large set of enterprise data in the Microsoft Graph (opens in new tab). The graph currently contains context from over 18 trillion resources, including emails, events, users, files and more. This massive repository can be compliantly leveraged to create powerful knowledge extraction models and create a bespoke set of topics for each customer. Today, data from the Graph is used to power the knowledge experiences for all customers of Microsoft Viva Topics.
What are Topics?
Viva Topics automatically creates an enterprise knowledge base structured around topics, such as projects, events, and organizations, with related metadata about people, content, acronyms, definitions, conversations and related topics. Topic cards connect the user to knowledge in apps like SharePoint, Teams, Microsoft Search and more. Read more about topic discovery (opens in new tab).

Knowledge should not be locked in a repository but instead should be useful and consumable where it is needed. Putting topics in the flow of everyday work makes knowledge from across an organization more easily discoverable and actionable.
Part 2: Alexandria in Viva Topics
Viva Topics brings together the richness and breadth of technology investments from across Microsoft.
The different technologies have their own specialty for the rich metadata they can contribute to Viva Topics. For example, one technology specializes in delivering a definition for a topic or bringing in a relevant synopsis from Wikipedia. Alexandria technology is then used to bring all this knowledge together into one coherent knowledge base.
Naomi Moneypenny, who leads Viva Topics product development, describes the collaboration: “The Project Alexandria team and technologies have been instrumental to delivering the innovative experiences for customers in Viva Topics. We value their highly collaborative approach to working with many other specialist teams across Microsoft.”
Project Alexandria plays two fundamental roles in the production of Viva Topics:
- Topic mining: This process includes the discovery of topics in documents, as well as the maintenance and upkeep of those topics as documents change or as new documents are created.
- Topic linking: The process of bringing together knowledge from a variety of sources into a single unified knowledge base.
Alexandria achieves both tasks through a machine learning approach called probabilistic programming, which uses a special kind of program to describe the process by which topics and their properties are mentioned in documents. The same program can then effectively be run backwards to extract topics from documents. A big advantage of this approach is that information about the task is included in the probabilistic program itself, rather than using large amounts of labelled data. This enables the process to run unsupervised – it can perform these tasks automatically without any human input. For a technical description of the Alexandria probabilistic program see the award winning Alexandria Research Paper.
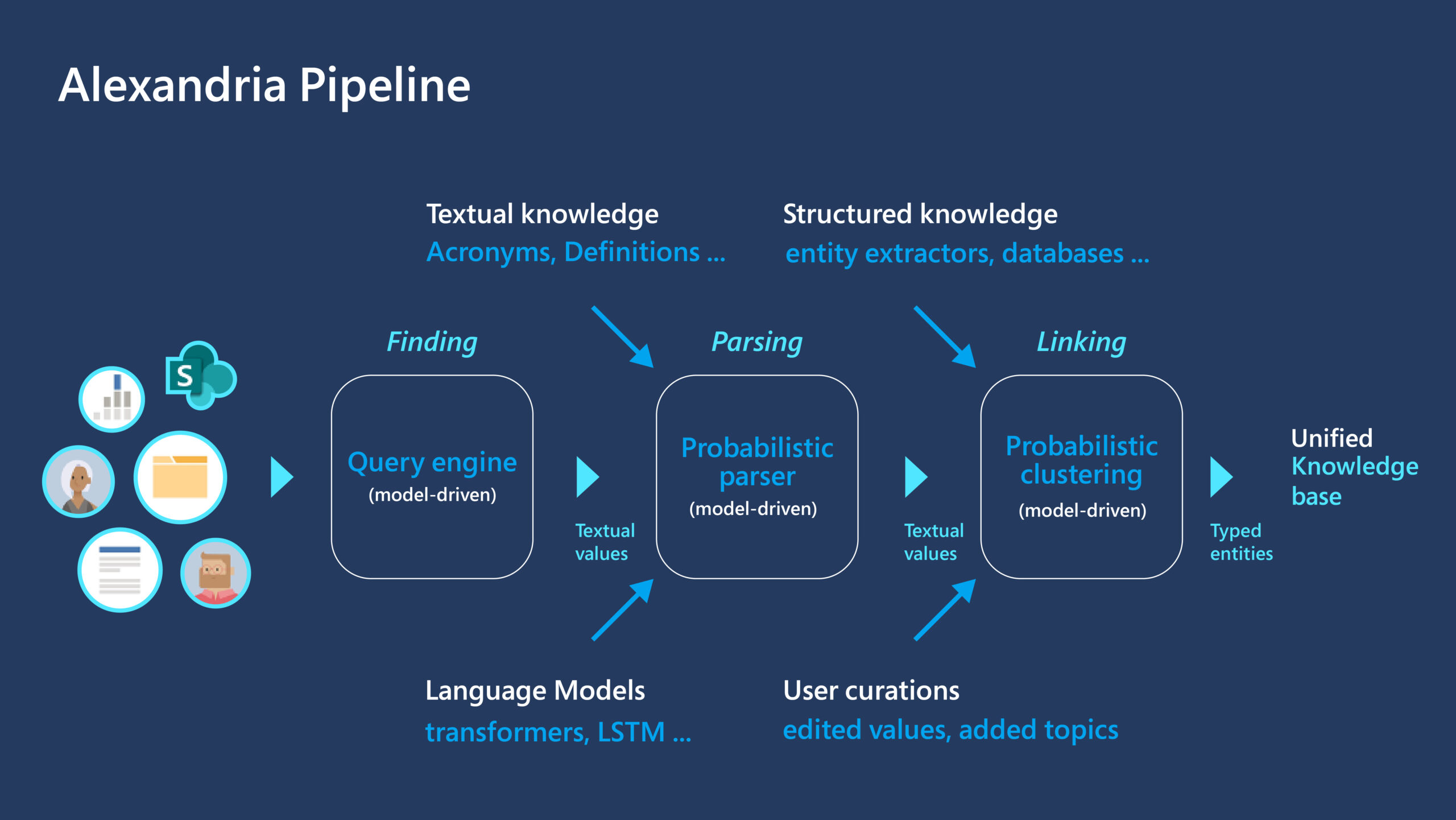
An overview of the process of mining and linking is shown in the picture below. Topic mining itself consists of two stages–finding relevant pieces of text and extracting knowledge from them using a probabilistic parser. Let’s have a more detailed look at each of these stages.

Alexandria topic mining
To narrow down the information needed to be processed, Alexandria first runs a query engine to extract snippets from each document with the high probability of containing knowledge. This query engine can scale to run over billions of documents. For example, say that the model was parsing a document related to a company initiative, Project Alpha. The query engine would extract phases likely to contain entity information, such as “Project Alpha will be released on 9/12/2021” or “Project Alpha is run by Jane Smith.”
The parsing process requires identifying which parts of the text snippet correspond to specific property values. In this approach, known as template matching, the model looks for a set of patterns, or templates, such as “Project {name} will be released on {date}”. By matching a template to the text, the process can identify which parts of the text correspond with certain properties. Alexandria performs unsupervised learning to create templates from both structured and unstructured text, and the model can readily work with thousands of templates. To improve coverage, templates can be augmented by a more sophisticated neural language model, such as an LSTM or a transformer, at increased computational cost.
We can extract textual property values from “Project Alpha will be released in 9/12/2021” using the template “Project {name} will be released on {completion_date}”. This gives the text “Alpha” for name and “9/12/2021” for completion_date. These strings come with inherent uncertainty in terms of what values they represent. For example, the completion_date string could represent the date 12th September 2021 or the date 9th December 2021, depending on which date format was used (D/M/YYYY or M/D/YYYY). To handle such uncertainty, Alexandria represents values as probability distributions over strongly typed values – in this case, dates. Here, the probability distribution would retain both possible dates. If another source contained the text “Project Alpha will be released on September 12”, then one of the possibilities would be eliminated, leaving the extracted date as 12th September 2021.
This parsing process is achieved by running the probabilistic program backwards using the Infer.NET machine learning framework. Infer.NET uses a process of message-parsing, as shown in the example below, which illustrates parsing the text “Project Alpha will be released on 9/12/2021”:
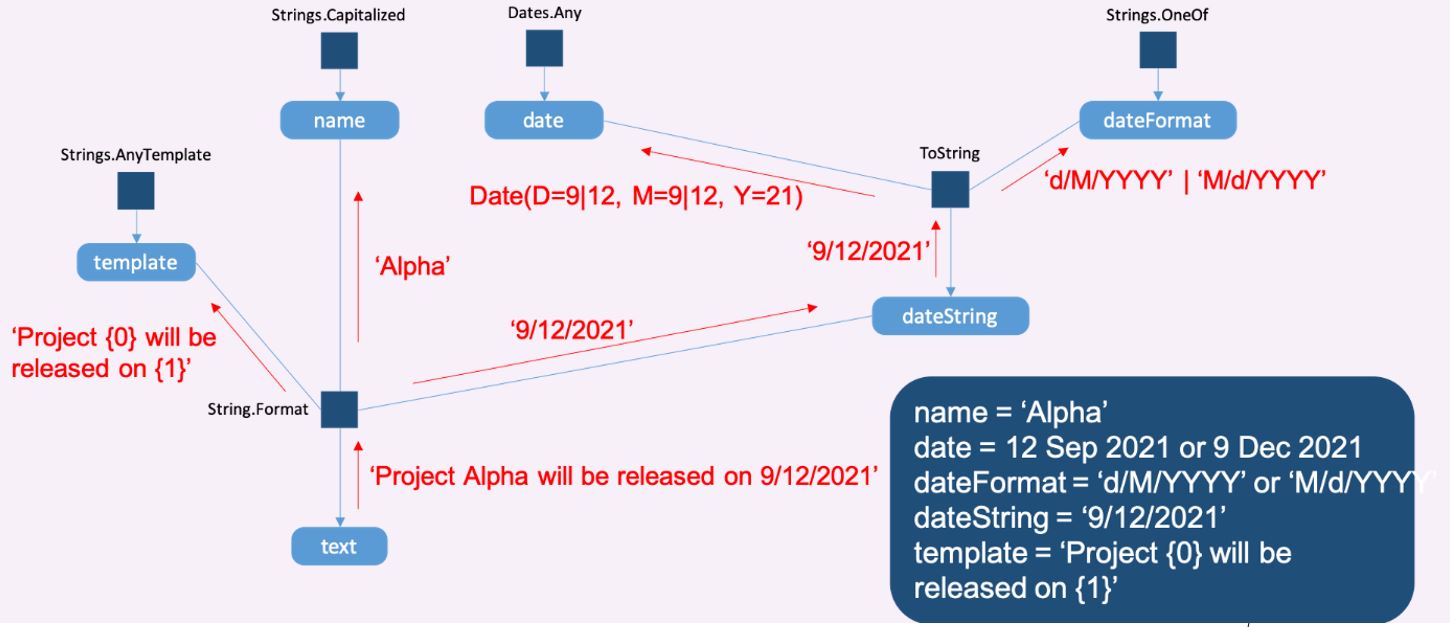
The output of probabilistic parsing is a probabilistic entity consisting of a set of properties and distributions over the values of these properties. Each parsed text extract gives rise to one such probabilistic entity, leading to a very large number. To combine these together, they are passed to the next stage: linking.
Alexandria topic Linking
The set of probabilistic entities coming out of the parsing stage typically contains many items which correspond to the same real-world entity. For example, we may have these two entities:
- {Name = Project Alpha, Completion-Date = September 2021}
- {Name = Alpha, Completion-Date = 12 September, Owner = Jane Smith}.
The linking process identifies duplicate or overlapping entities and merges them using a clustering process driven by the same underlying probabilistic program as used for parsing. This ensures consistency throughout the Alexandria pipeline.
When considering whether to link two entities, the linker makes use of the distributions over their property values. It calculates whether it is more likely that both distributions arose from a single underlying value or from two different values. In the example above, there is an underlying entity whose values are consistent with both entities, which is the merged entity:
- {Name = Project Alpha, Completion Date = 12 September 2021, Owner = Jane Smith}.
Typically, many hundreds or thousands of items are merged together to create more robust entries along with a detailed description of the extracted entity.
The above example is a simple one. In practice, the linking process must analyze more complex values to identify compatibility. For example, if one document says Project Alpha is owned by “Jane Smith” and another says the Project is owned by “Jane”, they may be indicating the same person. Similarly, documents referring to “Project Alpha” or just “Alpha” may refer to the same project.
Alexandria’s probabilistic program can also help sort out errors introduced by humans. A document indicating “Project Alpha is owned by Jay Smith” instead of Jane Smith may refer to the same entity, even though the project owner was recorded incorrectly.
The linking process can also analyze knowledge coming from other sources, even if that knowledge was not mined from a document. This allows processing of structured data from databases, other knowledge mining toolkits and even manually curated knowledge. Wherever the information comes from, it is linked together to provide a single unified knowledge base.
Linking can also be applied incrementally, so that information is processed as it arrives, continually updating the knowledge base.
Part 3: The Future of Alexandria
The enterprise knowledge base will soon be internationalized, allowing information in multiple languages to be brought together in a single knowledge base. Particularly useful for international organizations, this update will come with a feature that can automatically translate extracted knowledge.
Looking further ahead, Alexandria’s ability to extract information automatically gives us the opportunity to customize the knowledge discovery process. By automatically retrieving the set of types and properties being talked about in an organization’s documents, Alexandria can create a knowledge base with a bespoke schema exactly tailored to the needs of each organization and using the familiar language and terminology that people in the organization are used to. Read more about the proposed schema-based design in our research paper.
We are only beginning to dream of the experiences that an automatically created and updated knowledge base can enable, but it is already clear that it could transform the future of how we work. The era of big knowledge is coming sooner than you might think.
Resources and Further Reading